项目实践
从真实问题出发,完成需求定义、技术方案设计、产品实现与结果验证
WakeyTasky:ADHD任务拆解桌面工具
面向ADHD及任务启动困难人群,将用户输入的模糊目标转化为可编辑、可追踪的行动计划,让 AI 从“给建议”进入真实任务执行流程。
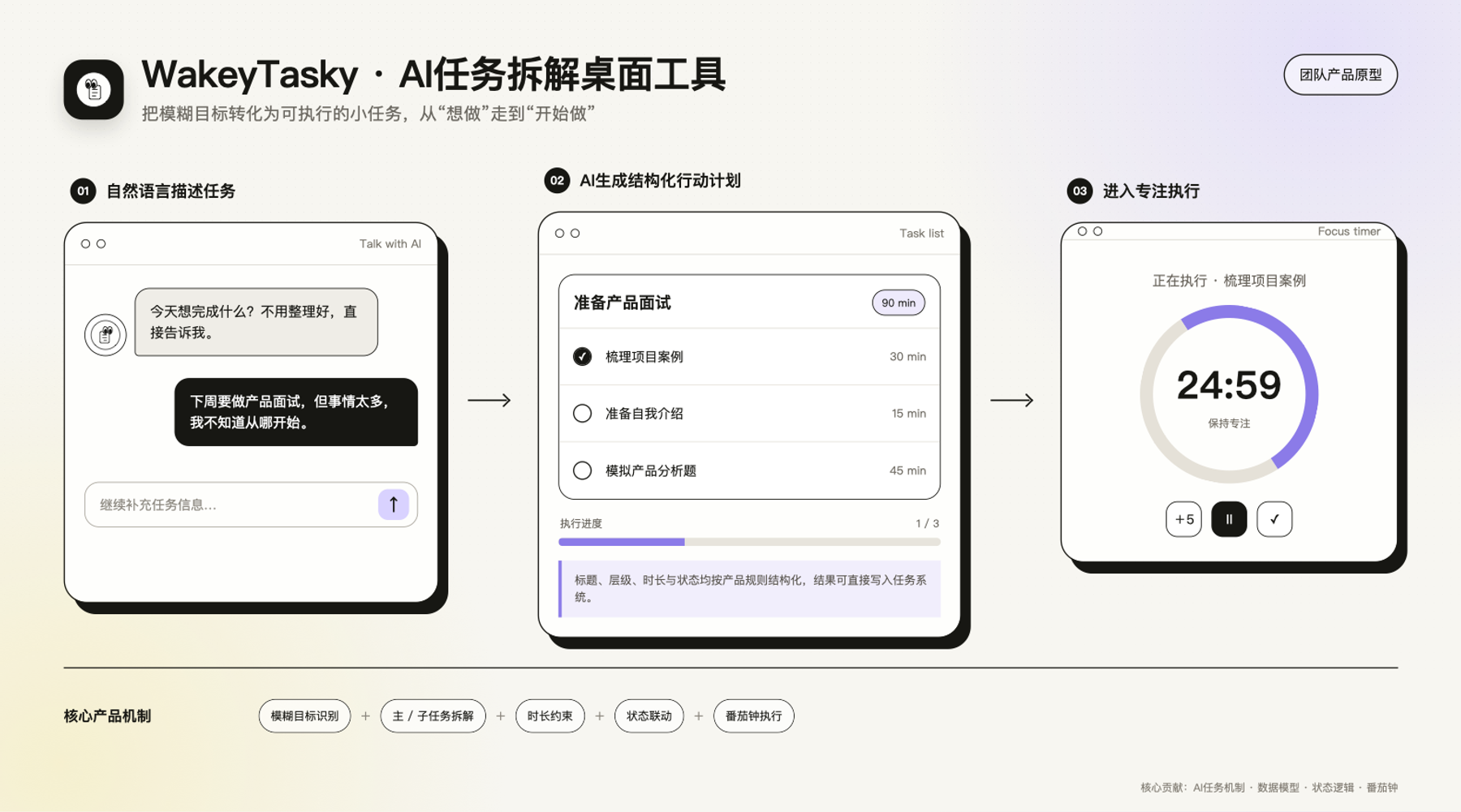
- 定义任务拆解产品机制:
- 将 MVP 从泛化日程管理收敛至任务拆解+时长估算,设计“自然语言输入 - 任务分级生成 - 执行状态管理”核心流程;将“可执行”转化为任务层级、时长及状态枚举等明确输出标准,降低模型输出的不确定性
- 设计从 AI 建议到实际执行的闭环:
- 避免模型只返回一次性文字建议,将生成结果直接转化为可编辑的任务结构,并设计子任务进度联动、完成状态回写及番茄钟执行流程,使用户能够从模糊目标直接进入具体行动
- 推动产品规则落地为可运行原型:
- 负责 AI 输出约束、任务数据模型及核心状态逻辑,并与团队共同完成 Electron 桌面端、LLM 与本地任务系统的集成,验证核心方案的技术可行性
Voluma:AI 建筑平面图 3D 渲染工具
面向建筑与室内设计场景,用结构化约束将图像生成模型收敛到“几何忠实于原图”的专业要求。
- 将 UX 需求转译为模型约束:
- 针对建筑师“几何保真、材质真实”的核心诉求,横向测试 4 款多模态模型,以几何还原度而非渲染美观度作为核心评估标准;最终选择 Gemini 2.5 Flash Image,兼顾结构化空间输入的指令遵从度与生成成本
- 通过 7 版 Prompt 迭代,将“去除标注”“保持比例”等抽象体验要求转化为可稳定复现的约束规则,抑制模型过度生成
- 基于用户反馈迭代产品决策:
- 独立实现 2D→3D 渲染全流程,支持一键导出与社区分享;与 3 位建筑设计师开展可用性测试,并根据反馈调整约束优先级,使生成结果满足专业工作流的最低可用标准
照护者画像数据浏览器
基于 997 行、68 列的真实照护者调研原始数据,构建可复用的画像数据集与交互式浏览产品,帮助用户理解照护者的特征、行为和核心需求。

- 从产品需求反推数据模型:
- 围绕画像卡片、行为与需求洞察、分布图表等 8 个产品模块,完成原始字段到产品功能的映射,明确派生、保留与删除字段,并划分数据预处理和前端实时生成逻辑
- 将脏数据治理为可信数据集:
- 识别隐藏字符、字段缺失与非标准标记值等隐性故障;定义分阶段过滤、字段转换、异常中止和验收规则,并记录各阶段数据损耗,使清洗过程可审计、可复现
- 设计确定性画像生成逻辑与数据规范:
- 基于年龄、工作时长等真实字段定义职业分类,为姓名、年龄、职业和头像设计带年龄适配与概率约束的匹配规则;将生成结果在清洗阶段一次性固化,兼顾画像多样性、现实合理性与跨页面一致性
可复用训练数据生成方案·安卓恶意软件检测
面向安卓恶意软件检测研究,识别出“一批训练数据”背后的真实瓶颈,将研究方向重新定义为交付可直接复用的数据集与数据生成能力。
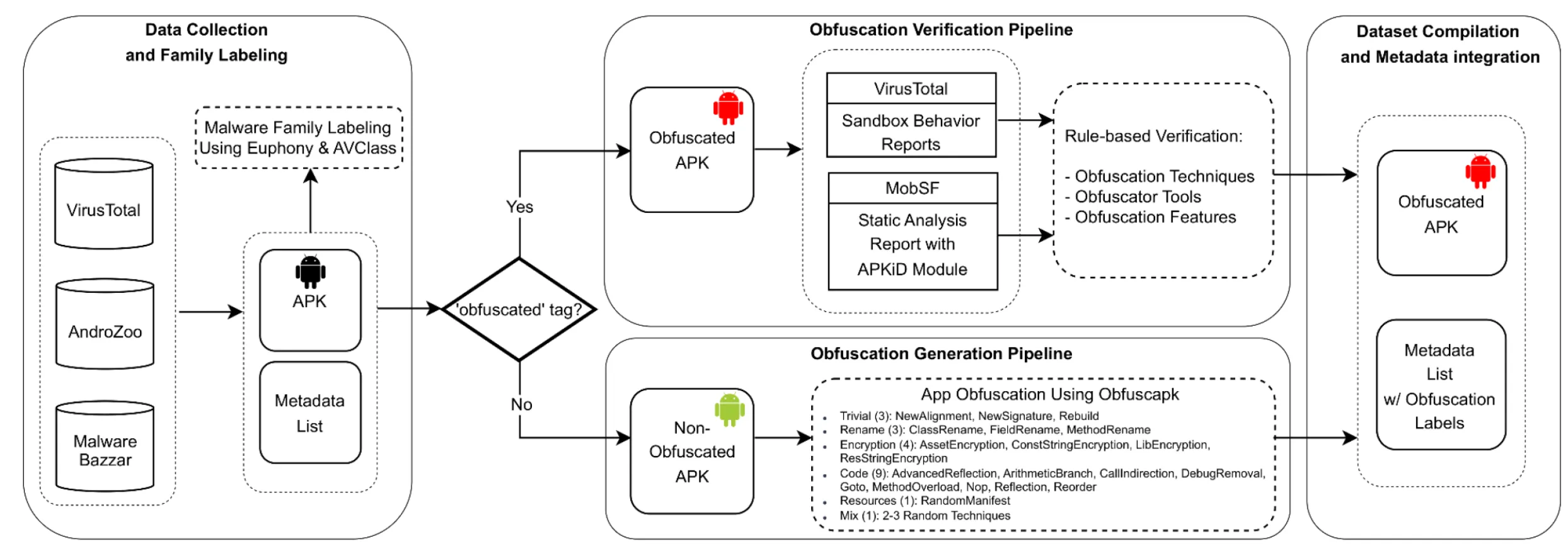
- 识别真实痛点并重构产品方案:
- 针对公开数据集陈旧、缺少细粒度混淆标签,以及生成过程不可复现的问题,将一次性处理脚本重构为生成与验证解耦的双流水线架构,使各阶段能够独立监控、重试和扩展,最终成功混淆率约 89%
- 定义可扩展的数据生成策略:
- 整合 4 大类、17 种混淆策略覆盖主流对抗手段;针对不同工具成功率差异设计三阶段 fallback 策略,并通过标签诚实标注方法边界
- 累计处理 13,000+ 样本,生成 6,700+ 有效变种,交付可供研究者直接用于后续训练、无需重跑脚本的数据集